One of the most important books that was written in the field of machine learning ,that is easily accessible to a broad range of audience, is hands-on machine learning. Throughout a series of posts, I will try to explain its main concepts, a chapter by chapter. In this post, the first chapter is explained throughy.
Machine learning applications are being deployed in all areas. From telecommunications to forecasting, all those applications help business decision making, and daily activities to make a better life. Facebook advertising is one example of such application that is so common to spot among the public. The following table is a summary of some applications:
| Applications | Best Models | Domain |
|---|---|---|
| visual inspection defect | CNN, Transformers | CV |
| Text summarisation | RNN, CNN, Transformers | NLP |
| Forecasting revenue | SVM, RNN, CNN, Transformers | Forecasting |
| Fraud detection | Gaussian mixtures, Auto encoders | Finance, Banking |
| Customer segmentation | K-means, DBSCAN | Advertising, Social media analytics |
What is Machine learning
Machine learning has a long history with different difinitions according to the era. The two most prevalent definitions of machine learning are:
- Arthur Samuel
- Field of study that gives computers the ability to learn without being explicitly programmed
- Tom Mitchell
- A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
The two definitions are quite interesting, but the second one is a little bit more accurate.
Types of Machine learning
The following diagram is a concptual representation of the different categories of machine learning algorithms:
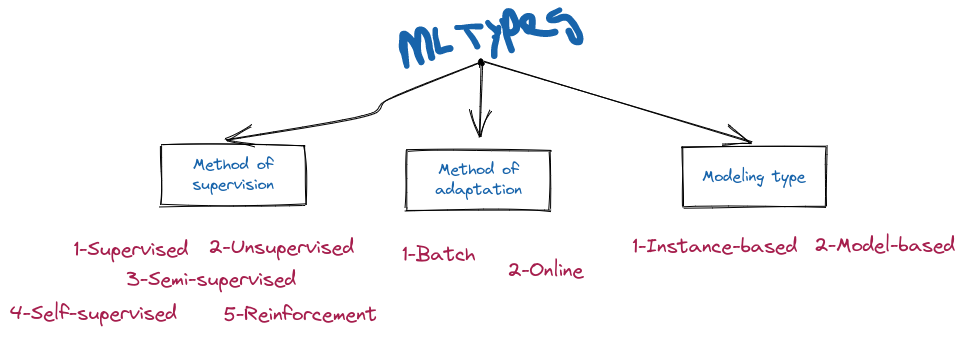
Category 1: Method of supervision (Training type)
In this category, the idea is to classify the algorithms according to the way they are trained. The two main types are:
- Supervised learning
- The algorithm is trained with labeled data. The algorithm learns from the data and tries to predict the label of new data. The two main types of supervised learning are classification and regression.
- Unsupervised learning
- The algorithm is trained with unlabeled data. The algorithm tries to find patterns in the data. The two main types of unsupervised learning are clustering and dimensionality reduction.
Category 2: Method of adaptation
This is how the algorithm adapts to new data. The two main types are:
- Batch learning
- The algorithm is trained with all the data available. The algorithm is then deployed to production. The algorithm is not trained again unless new data is available.
- Online learning
- The algorithm is trained with a small batch of data. The algorithm is then deployed to production. The algorithm is trained again with new data as it becomes available.
Category 3: Method of generalization (modeling type)
This is how the algorithm generalizes to new data. The two main types are:
- Instance-based learning
- The algorithm is trained with labeled data. The algorithm learns from the data and tries to predict the label of new data. The two main types of instance-based learning are classification and regression.
- Model-based learning
- The algorithm is trained with labeled data. The algorithm learns from the data and tries to predict the label of new data. The two main types of model-based learning are classification and regression.
Main challenges in Machine learning
We said that machine learning is a field of study where yoy learn from a training set by describing it using a model. So, we have two things that could go wrong: Data and Model. The following are the two families of things that could go wrong.
Data Problems
- Insuffiecnt quantity of training data.
There is an unresonable effect of the quantity of data on the performance of the model. In a study in 2011, it was shown that the performance of a model increases with the quantity of data. The following figure is a representation of the effect of the quantity of data on the performance of the model:
- Non-representative training data
You need your data to be representitve enough for all the cases you want to predict. For example, if you want to predict the price of a house, you need to have data that is representative of the price of the house. If you don’t have data that is representative of the price of the house, you will have a model that is not accurate enough.
- Poor-quality data
The data could be noisy, or it could have missing features. This could happen due to different reasons, for example, the data could be corrupted, or the data could be missing some features or the data collection process resulted in such damage.
- Irrelevant features
Model Problems
- Overfitting the training data
- Underfitting the training data
Testing and validation
The following diagram is a concptual representation of the main challenges in machine learning: