Federated learning is a very hot topic in the current machine learning spectrum. We can clearly see the word being advertised in many conferences, papers, and even youtube videos and meduim articles. With this hype it’s our duty to dig deeper to understand what is it all about. In this post we will try to understand the concept of federated learning and how it can be applied in real life. My goal is to summarize the technical survey published in 2021 titled Advances and open problems in Federated Learning.
The term Federated Learning is not a new sub-field of machine learning (it’s not like deep learning), it’s just a new setting for solving machine learning problems with privacy in mind. The idea is to train a model on a distributed dataset without sharing the data with a central server. This is done by training the model on each client’s data and then aggregating the model parameters to the server. The server then sends the updated model to the clients to continue the training process. This process is repeated until the model converges.
The following figure illustrates a very basic federated learning process:
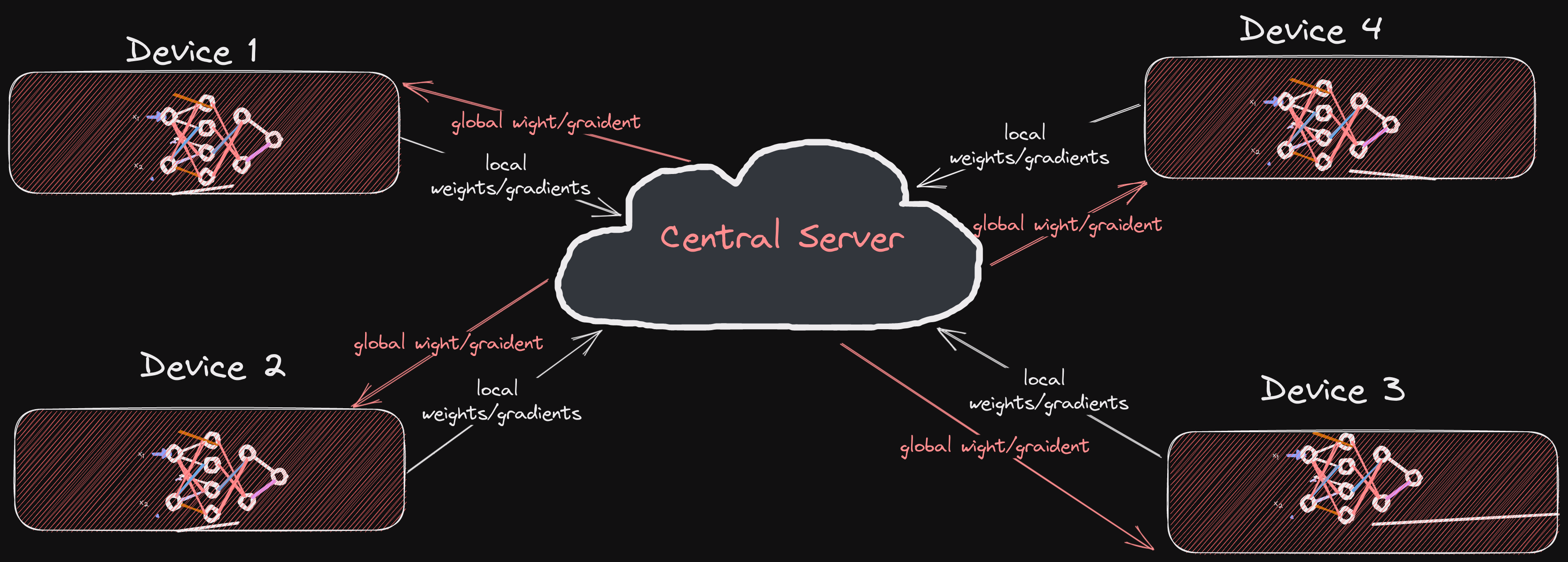
So, the basic idea is:
- A bunch of devices (clients) train a model locally using their own data.
- The model parameters are sent to a central server.
- The server aggregates the model parameters and sends the updated model to the clients.
- The clients continue the training process using the updated model.
Having stated the basic setting of a federated learning problem, we will continue investigating the challenges and open problems in the field, one by one, and try to understand the proposed solutions and current state of the art techniques. we finsih by listing a set of tools and frameworks that can be used to implement federated learning algorithms in practice.
Introduction
The term Federated Learning was introduce in 2016 bt McMahan et al. The paper defined a set of challenges as the core assumptions of FL systems.
Although the initial work of federated learning focused on cross-device learning, the interest has grown to include what we call cross-silo setting. So, the natural question should be: what are cross-device and cross-silo settings?
Cross-device setting: the data is distributed across multiple devices (clients). One example of this is Google Keyboard Gboard, where the data is distributed across multiple mobile devices. The clients here are mobile/edge devices. The data is stored in the messaging app (locally). and the model is trained on the device and the updated model is sent to the server.
Cross-silo setting: the data is distributed across multiple organizations’s servers (silos). This could happen where different hospitals come together to train a model to solve a medical problem without sharing the data with a central server. The clients here are not mobile/edge devices, rather, they are the organization’s servers.
The lifecycle of a model training in Federated learning
- Client Selection
- BroadCasting.
- Client Computation.
- Aggregation.
- Model Update.
Relaxing the core FL assumptions: Emerging settings and Scenarios
In this section, a handful of emerging settings and scenarios are discussed. The goal is to understand the challenges and open problems in each setting and scenario and how they can solve FL problems in such settings.